
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 패스트캠퍼스
- 국비지원취업
- AI부트캠프
- 업스테이지AILab
- Ai
- upstage
- KPT
- #왕십리 #성동구 #중랑구 #동대문구 #중구 #광진구 #성북구 #가산디지털 #금천구 #신도림테크노 #양천구 #영등포구 #디엠씨 #dmc #마포구 #은평구 #서대문구 #중구 #종로구 #강서구 #동작구 #관악구 #구로구 #동작구 #강남구 #송파구 #도봉구 #서초구 #노원구 #일산 #의정부 #양평 #양주 #고양 #성북구 #경기도 #서울 #휴대폰성지 #휴대폰최저가 #휴대폰
- 회고
- 패스트캠퍼스업스테이지에이아이랩
- 패스트캠퍼스AI부트캠프
- 무료교육
- UpstageAILab
- 업스테이지패스트캠퍼스
- AI 부트캠프
- 국비지원
- 부트캠프
- 패스트캠퍼스부트캠프
- ai 취업
- 데이터분석
- 데이터사이언스
- 12월3주차
- 패스트캠퍼스 #패스트캠퍼스AI부트캠프 #업스테이지패스트캠퍼스 #UpstageAILab#국비지원 #패스트캠퍼스업스테이지에이아이랩#패스트캠퍼스업스테이지부트
- 취업 포트폴리오
- 패스트캠퍼스업스테이지
- 패스트캠퍼스업스테이지부트캠프
- Today
- Total
차근차근잼
[2023 부트캠프] Upstage AI Lab - ML 프로젝트 중간 진행 상황 본문
[2023 부트캠프] Upstage AI Lab - ML 프로젝트 중간 진행 상황
매울신현구 2024. 2. 26. 17:43
1차 발표를 마치고 지금까지 진행한 프로젝트 내용을 발표자료를 이용해 간략히 정리하고자 한다.
EEG 자체에 대한 이해가 시간이 걸려서 이미지 모델을 구현하겠다는 원대한 꿈은 아직 발표에 녹여내지 못했고 추후에 더 발전된 모습으로..... 공유를 하기로 하였다..!
1차적으로 데이터 이해한 부분, EDA 및 인사이트, 결론, 앞으로 할 일을 공유해보고자 한다!!
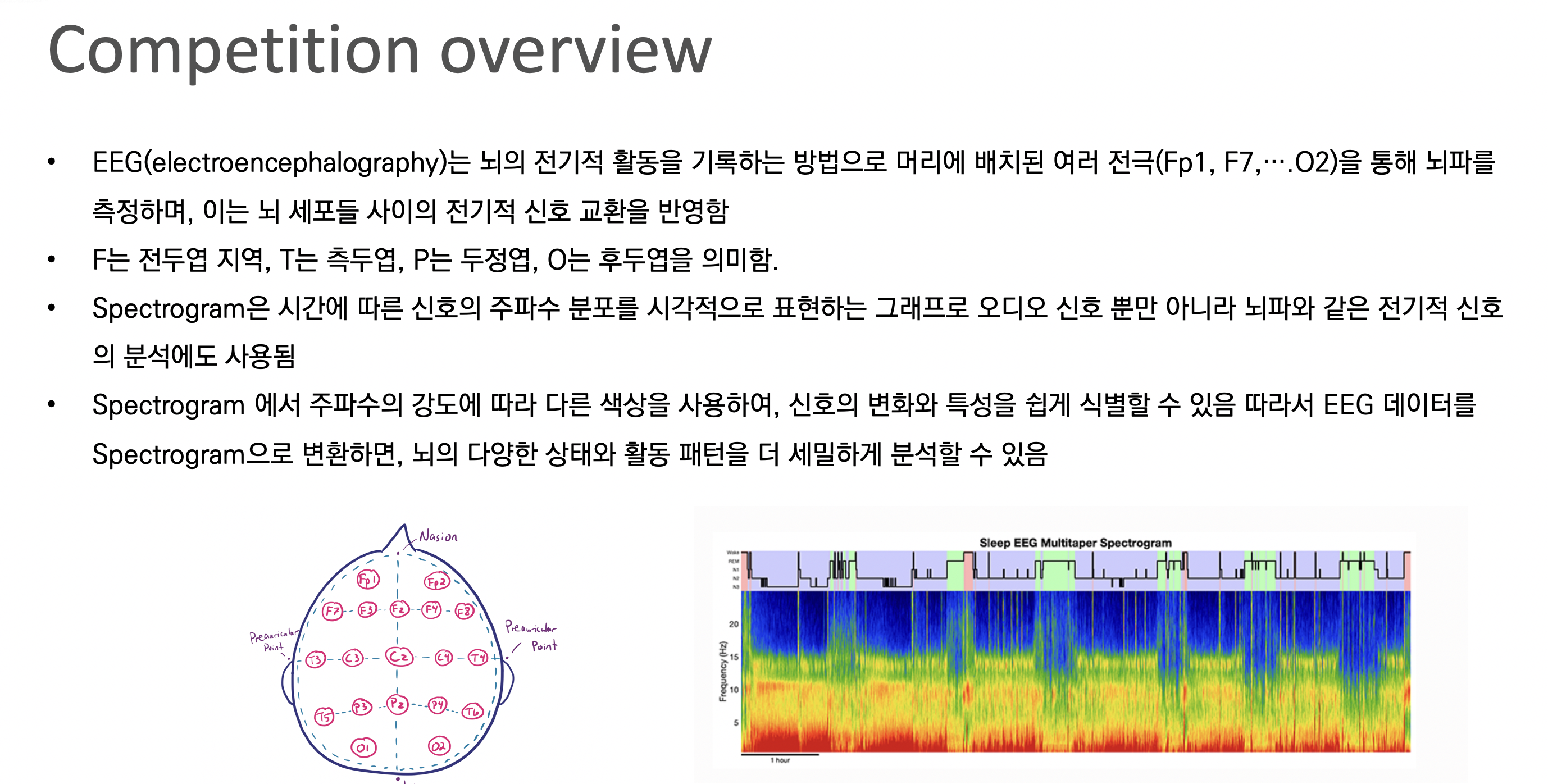
EEG 측정은 여러 방법이 있는데 여기서는 10-20 rule? 을 적용해 머리를 전두엽, 측두엽, 두정엽, 후두엽으로 나누어 전극을 배치하고 측정된 신호를 시간-주파수의 Spectrogram으로 표현한다. 이는 주파수의 강도에 따라 다른 색상을 사용해 분석에 용이하게 하기 위함이다. 실제로 이 데이터를 이용해 전문가가 뇌의 다양한 상태와 앞으로의 상태를 예측한다고 한다.

자세히 보면 각 전극의 전압차를 이용해 전극의 체인을 형성하고 이를 통해 EEG 값의 변화를 추적하는 과정이라고 할 수 있다.
이 데이터에서는 Bipolar montage라는 분석 기법을 사용한다. 이 방법이 가장 일방적인 분석 방법이라고 한다.

대회에서 사용되는 평가기준은 Kullback-Leibler divergence로, 간단히 말해 현실과 이상의 괴리를 나타내는 지표로 볼 수 있다.
즉, 예측값과 실제값의 분산의 차이를 나타내며 이는 작을수록 유사하다고 판단이 되고, Classification 문제의 cross-entropy의 개념과
비슷한 정보량의 차이로 이해해도 된다고 한다.

이제 복잡한 데이터의 대략적인 모습을 확인해보자.
train.csv는 train 데이터의 메타데이터로, EEG ID,..., Spectrogram ID 기타 등등 그리고 target 값이 존재하고 이에 매칭되는 EEG ID, Spectrgram ID 마다 각각의 parquet 파일이 제공된다.
test.csv 는 1 row로 구성되어 있으며 parquet 파일의 구성은 train 데이터와 동일하다.
보면 메타데이터에 중복이 많다. 이번 데이터를 이해하는데 첫 번째 장애 요소였는데 아래 그림을 보면서 차근차근 이해해 보도록 하자.

EEG ID 가 여러 개 나오는 이유는 time window를 따라 데이터를 중복으로 나타내기 때문이다. EEG는 50s의 time window를 사용하고 spectrogram은 600s의 time window를 사용한다. 그리고 이 두 데이터가 겹치는 10s에 대해 target을 예측한다.
또 앞서 설명한 것처럼 Spectrogram이 여러 개의 EEG를 참조하는 경우도 발생한다. 어떻게 측정을 하는지는 아직 명확하지는 않다....

대략적으로 이해가 되고 있다!
이제 target을 분석해 보자. target은 6개의 multi label로 각 label에 비교적 고르게 분포하는 것으로 보이고 label끼리의 상관관계도 크게 문제는 없어 보인다.
Seizure는 확실한 패턴이 있는 것으로 판단되고, Other에 대한 분류가 어려워 보인다.

EEG parquet 파일을 뜯어보았다.
전체적으로 신호에 noise가 많고 특히 심장 시그널인 EKG의 상태가 심각해 보여 보정을 해보았다.
이 작업을 전체적으로 거친다면 성능이 좋아질까?

Spectrogram parquet 파일을 뜯어보았다.
현재는 mel_spectrogram을 대부분 이용해 이미지로 변환하는 것 같은데 이것을 변경해 보는 방법을 실험해 보면 좋을 것 같고
Bipolar montage 방법에는 사용되지 않았던 중앙 부분 신호(Fz, Cz, Pz)와 귀 쪽 신호(A1, A2)를 사용해서 분석해 보는 방법을 실험해 보면 좋을 것 같다.

Hidden Test data에 대한 부분이 좀 신기하고 처음 해보는 일인데
보통 실무에서도 실제 데이터에 대한 예측을 하기 때문에 흥미로운 주제였다.
일단 중복되는 데이터가 많은데 어떤 데이터를 기준으로 예측을 하는 게 더 성능이 좋을까 하는 실험이 이미 kaggle에서 이루어진 상태였는데 Spectrogram 보다는 EEG를 기준으로 예측하는 것이 LB 향상에 더 도움이 되었다고 한다.
또 submission OOM과 shake up 등에 대한 예측을 위해 누군가 직접 time을 계산해 hidden test data의 row 수를 예측해 본 결과 약 2,640 Unique EEG id를 가질 것으로 보인다고 한다.

음... 별로 좋지 않았던 Feature Engineering....


강사님 피드백..!!
EEG 신호 자체를 이해하는 게 중요하다
- 패턴, 시각화, 노이즈 분석, 이상치 제거 등 데이터 자체에 대한 이해도가 중요해 보임
현재까지 1D Resnet-GRU 모델이 상위권
- 요즘 유행인 ViT계열의 큰 사이즈 모델 transfer learning
- efficient b0~ b4 차이가 있다? -> 성능 올라갔다? 그럼 큰 사이즈 모델(ViT)을 사용한다.라고 보통 판단하심
- resource 고민, 35/65% 로 나뉜 만큼 큰 모델을 사용하면 오버피팅의 문제도 있음
- efficient b0~ b4 차이가 없다? -> 모델 크기가 중요한 건 아님 augmentation이나 다른 방법을 고려해봐야 함
- ex) EfficientNetB0 -> EfficientNetB4 -> EfficientNetV2
Research code competition 인 만큼 많이 읽어 보고 공부해봐야 함
'공부 > 23' 패스트캠퍼스 Upstage AI 부트캠프' 카테고리의 다른 글
| [2023 부트캠프] Upstage AI Lab - Image Competition (1) | 2024.04.25 |
|---|---|
| [2023 부트캠프] Upstage AI Lab - Pytorch를 이용한 CNN (0) | 2024.03.15 |
| [2023 부트캠프] Upstage AI Lab - ML 프로젝트 데이터이해 (0) | 2024.02.22 |
| [2023 부트캠프] Upstage AI Lab - 자료구조와 알고리즘 (a.k.a. 코테) (0) | 2024.02.15 |
| [2023 부트캠프] Upstage AI Lab - Machine Learning (0) | 2024.02.02 |

